Training robots to manipulate soft and deformable objects
A virtual environment embedded with knowledge of the physical world speeds up problem-solving.


Robots can solve a Rubik’s cube and navigate the rugged terrain of Mars, but they struggle with simple tasks like rolling out a piece of dough or handling a pair of chopsticks. Even with mountains of data, clear instructions, and extensive training, they have a difficult time with tasks easily picked up by a child.
A new simulation environment, PlasticineLab, is designed to make robot learning more intuitive. By building knowledge of the physical world into the simulator, the researchers hope to make it easier to train robots to manipulate real-world objects and materials that often bend and deform without returning to their original shape. Developed by researchers at MIT, the MIT-IBM Watson AI Lab, and University of California at San Diego, the simulator was launched at the International Conference on Learning Representations in May.
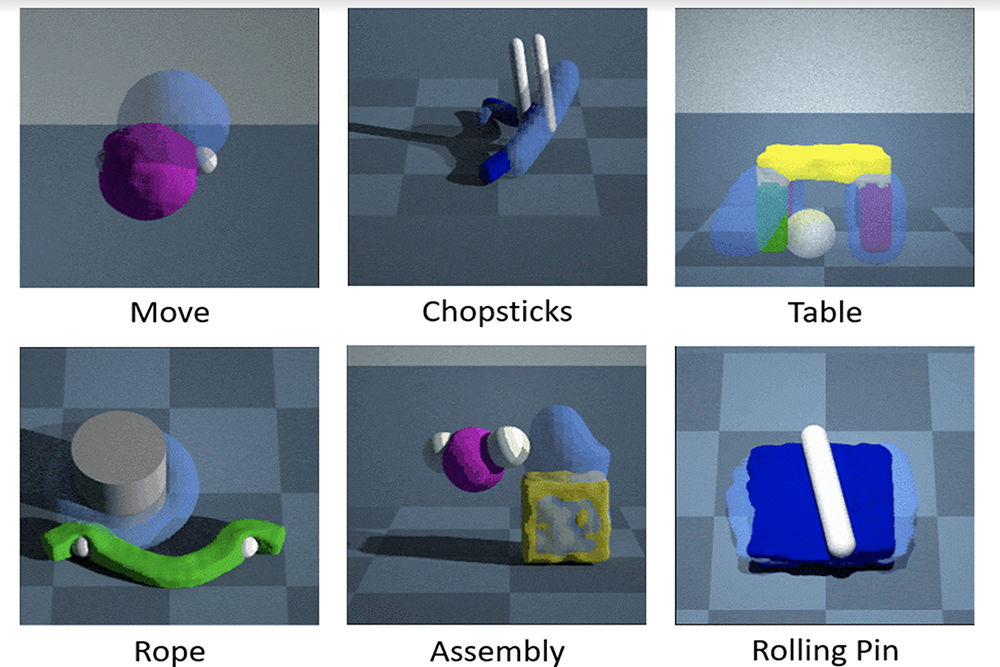
In PlasticineLab, the robot agent learns how to complete a range of given tasks by manipulating various soft objects in simulation. In RollingPin, the goal is to flatten a piece of dough by pressing on it or rolling over it with a pin; in Rope, to wind a rope around a pillar; and in Chopsticks, to pick up a rope and move it to a target location.
The researchers trained their agent to complete these and other tasks faster than agents trained under reinforcement-learning algorithms, they say, by embedding physical knowledge of the world into the simulator, which allowed them to leverage gradient descent-based optimization techniques to find the best solution.
“Programming a basic knowledge of physics into the simulator makes the learning process more efficient,” says the study’s lead author, Zhiao Huang, a former MIT-IBM Watson AI Lab intern who is now a PhD student at the University of California at San Diego. “This gives the robot a more intuitive sense of the real world, which is full of living things and deformable objects.”
“It can take thousands of iterations for a robot to master a task through the trial-and-error technique of reinforcement learning, which is commonly used to train robots in simulation,” says the work’s senior author, Chuang Gan, a researcher at IBM. “We show it can be done much faster by baking in some knowledge of physics, which allows the robot to use gradient-based planning algorithms to learn.”
Basic physics equations are baked in to PlasticineLab through a graphics programming language called Taichi. Both TaiChi and an earlier simulator that PlasticineLab is built on, ChainQueen, were developed by study co-author Yuanming Hu SM '19, PhD '21. Through the use of gradient-based planning algorithms, the agent in PlasticineLab is able to continuously compare its goal against the movements it has made to that point, leading to faster course-corrections.
“We can find the optimal solution through back propagation, the same technique used to train neural networks,” says study co-author Tao Du, a PhD student at MIT. “Back propagation gives the agent the feedback it needs to update its actions to reach its goal more quickly.”
The work is part of an ongoing effort to endow robots with more common sense so that they one day might be capable of cooking, cleaning, folding the laundry, and performing other mundane tasks in the real world.
Other authors of PlasticineLab are Siyuan Zhou of Peking University, Hao Su of UCSD, and MIT Professor Joshua Tenenbaum.