
















A Packet-based Architecture For Edge AI Inference
This blog post was originally published at Expedera’s website. It is reprinted here with the permission of Expedera. Despite significant improvements in throughput, edge AI accelerators (Neural Processing Units, or NPUs) are still often underutilized. Inefficient management of weights and activations leads to fewer available cores utilized for multiply-accumulate (MAC) operations. Edge AI applications frequently … A Packet-based Architecture For Edge AI Inference Read More + The post A Packet-based Architecture For Edge AI Inference appeared first on Edge AI and Vision Alliance.


This blog post was originally published at Expedera’s website. It is reprinted here with the permission of Expedera.
Despite significant improvements in throughput, edge AI accelerators (Neural Processing Units, or NPUs) are still often underutilized. Inefficient management of weights and activations leads to fewer available cores utilized for multiply-accumulate (MAC) operations. Edge AI applications frequently need to run on small, low-power devices, limiting the area and power allocated for memory and compute. Low utilization, sometimes referred to as dark silicon, means compute resources that could be used to run your application(s) more efficiently instead are standing idle and wasting power and area in your designs.
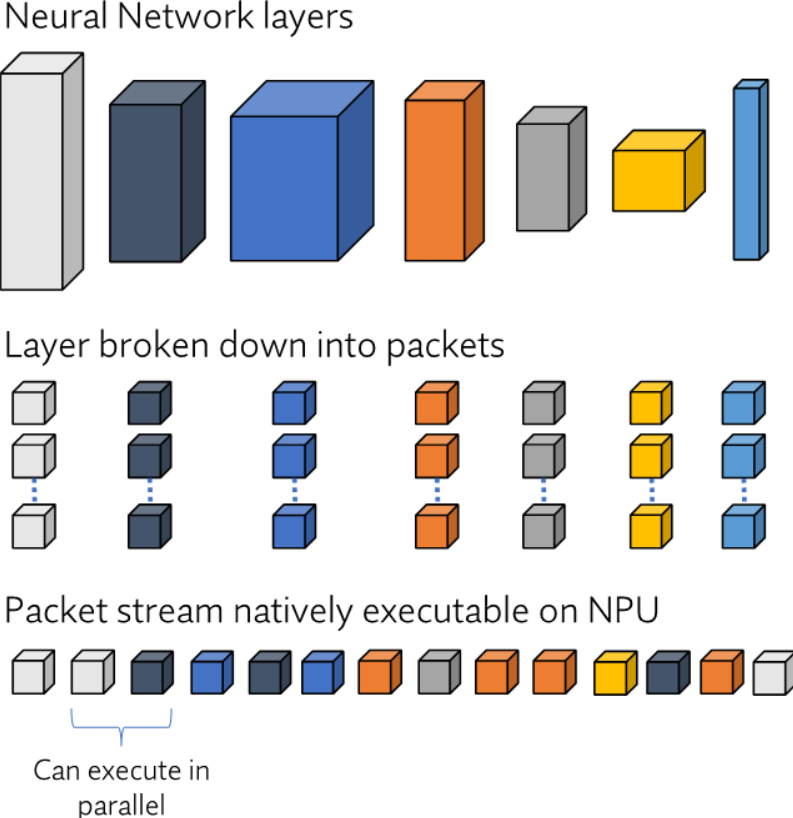
One way to increase NPU utilization is by optimizing the computation of activations during inference. Layerwise computation of activations is inefficient since it requires storing all the activations of the still-to-be-used layers of the neural network (NN) before proceeding to the next layer. An alternative is to understand the fine-grained dependencies in the network and create a computation order based on high-level objectives. This is done by breaking each layer into “packets” containing the metadata necessary to propagate activations through layers.
In this “packet-based” traversal of the network, an activation is removed from memory after it is no longer needed. This decreases the number of cycles needed to transfer activations to and from external memory (DDR). With sufficient on-chip memory, this approach eliminates activation moves to external memory altogether.
Optimizing network traversal through packets increases MAC utilization by enabling parallel computations and parallel memory access. In other words, the NPU delivers more operations per second for a given frequency and number of MAC cores. This in turn increases throughput without adding additional bandwidth or compute.
Packet-based optimization
Optimizing a network using packets occurs in two steps: (1) converting the NN into packets and (2) scheduling packets to create a packet stream. In the first step, each layer is broken into contiguous chunks of metadata (packets). The process by which layers are transformed into packets depends on the type of layer and general hardware requirements. For instance, the way in which a convolutional layer is split into packets may not be optimal for an attention head or LSTM block.
Packets that are optimal for serial compute and serial direct memory access (DMA) may not be best for parallel compute and parallel DMA. Similarly, multicore NPUs may have different packet requirements than single-core NPUs. The available NPU and external memory resources also impacts the creation and scheduling of packets.
After layers are broken into packets, these packets are then scheduled to run on the NPU. Instead of being partitioned by layer, a network is split into partitions determined by available NPU memory and external memory bandwidth. Within each partition, packets are scheduled deterministically, with efficient context switching. Since packets contain only the information required to compute the set of operations in each partition, they add very little memory overhead (in the order of tens of kilobytes).
Layer-wise vs. packet-based partitioning: YOLOv3
YOLO (You Only Look Once) is a common family of network architectures for low-latency object detection. The operations in YOLOv3 are primarily 1×1 and 3×3 convolutions connected by leaky rectified linear unit (ReLU) activation functions and skip connections. Consider the example of YOLOv3 with 608×608 RGB inputs and a batch size of two images. The model contains 63 million weights, 4.3 million of which are in the largest layer, and 235 million activations, 24 million of which are in the largest layer. In total, 280 billion operations are necessary to compute the output of this model.
Now consider running YOLOv3 on an NPU with 4 MB available on-chip memory. A typical NPU with layerwise partitioning would require transferring hundreds of millions of weights and activations to and from external memory. Think of the layer with 24 million activations: only one-sixth of this layer can be stored on-chip, and this is without accounting for the millions of weights necessary to compute these activations.
However, by intelligently scheduling and executing packets, it is possible to partition YOLOv3 to reduce DDR transfers by over 80%, as shown in figure 1.
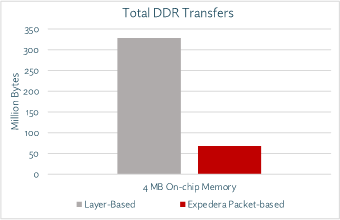
Fig. 1: Layer vs. packet-based memory needs.
Reducing the intermediate movement of tensors not only increases model throughput; it also lowers the power, memory, and DDR bandwidth required to attain a target latency. In turn, this decreases the area and cost required for the NPU and external memory. Moreover, large DDR transfers are typically required for some layers but not others. With packet-based partitioning, it is possible to decrease not only the external memory bandwidth required, but also the variance in the bandwidth across the network. This leads to lower variances in utilization, latency, power, and throughput – critical for applications running on edge devices.
Intelligent hardware for edge AI
The advantages of packets for reducing data storage and transfer and increasing model performance are evident from the above examples and not limited to YOLO or object detection networks. Any neural network can benefit from packet-based partitioning, such as autoencoders, vision transformers, language transformers, and diffusion networks – all of which are supported by Expedera’s architecture today. Packet-based partitioning also helps execute mixed precision models as well as networks with complex layer connectivity.
However, traditional hardware architectures are ill-served for managing the scheduling and execution of packets. Instruction-based architectures tend to have high overhead when scaling to multiple cores. Layer-based architectures require a large amount of memory, as shown in the example of partitioning YOLOv3.
The following diagram displays Expedera’s packet-based architecture, silicon-proven and deployed in more than 10 million devices. Unlike the instruction-based or layer-based abstractions, Expedera’s packet-based architecture contains logic for executing the packets natively and reordering those packets without penalty (zero-cost context switching). The architecture is flexible, scaling from 3.2 GOPS to 128 TOPS in a single core independent of memory.
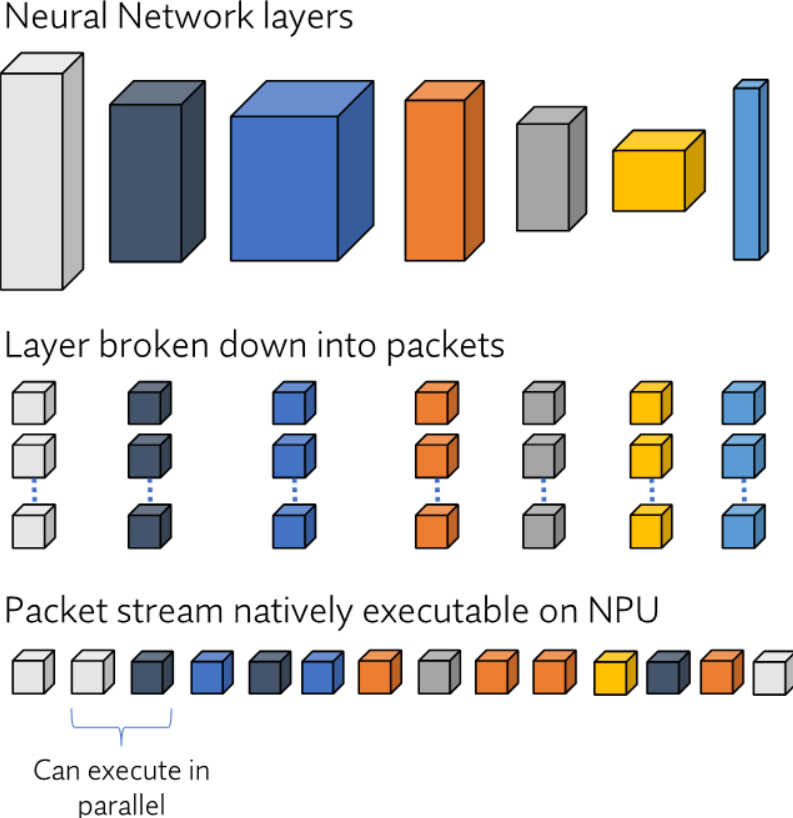
Fig. 2: Layer-to-packet process.
Deploying AI solutions in embedded devices demands hardware that is not only fast but efficient. As illustrated here, optimizing the flow of activations through a network can significantly reduce data transfers and memory overhead. The best hardware for edge AI tasks should not only be faster but smarter, effectively utilizing available resources by intelligently scheduling and executing operations.
The post A Packet-based Architecture For Edge AI Inference appeared first on Edge AI and Vision Alliance.

















